[MRG] ENH: K-Means SMOTE implementation #435
Conversation
Codecov Report
@@ Coverage Diff @@
## master #435 +/- ##
==========================================
- Coverage 98.9% 96.47% -2.44%
==========================================
Files 84 85 +1
Lines 5202 5329 +127
==========================================
- Hits 5145 5141 -4
- Misses 57 188 +131
Continue to review full report at Codecov.
|

|
@felix-last as the author and creator of the algorithm are you willing to review this PR? |
|
@chkoar @felix-last Thanks in advance for taking a look at this. It must be said that my initial research was somewhat poor, which caused me to neglect the existing implementation by the original author. As such, this is was programmed without actually looking at that code. I nevertheless thought it valuable to contribute this back to the project. |
|
Unfortunately I don't have time for a detailed review. Just a few comments after glancing over:
I'd like to point out that our implementation also complies with the imbalanced-learn API. |
|
@felix-last Sincere thanks for the lookover. I'll be happy to make these changes and push them to the project, provided @chkoar would still like it included. |
|
@StephanHeijl we are fine including new methods (I would be frilled to get something working on categorical data :)) until that we provide references. |
|
Hello @StephanHeijl! Thanks for updating this PR. We checked the lines you've touched for PEP 8 issues, and found:
Comment last updated at 2019-06-12 13:20:16 UTC |
|
@glemaitre I took some time to work out the last kinks and implement the edge cases from the paper, but I believe this can be subjected to a thorough review. |
|
Ok I will try to have a look |
|
The PR looks in general good. @chkoar Before to carry on a full review I have an API question. I am split between: (1) adding a new kind of SMOTE and adding 3 new parameters (as in this PR); In (1), I am scared that we will have to much parameters for the common case which is painful for the user. In (2), we will have 3 classes instead of 1. What are you thoughts @chkoar |
|
It seems that SMOTE class gets much responsibility. Also, according to this article there are almost 100 hundred published variations of SMOTE. So, I believe that option two is the way to go. We have to take care not to duplicate code between classes. |
|
OK so let's go for a base class @StephanHeijl I will make a PR and then you will need to move the code within a new class which will inherit from the base class. It should be a minimal change but quite beneficial. |
|
@glemaitre Will do, once the PR drops I'll integrate it and move the code. I agree that this should make SMOTE implementation a lot more accessible. |
|
@StephanHeijl I think that you can start to have a look to #440. |
imblearn/over_sampling/smote.py
Outdated
|
|
||
| svm_estimator : object, optional (default=SVC()) | ||
| If ``kind='svm'``, a parametrized :class:`sklearn.svm.SVC` | ||
| classifier can be passed. | ||
|
|
||
| n_kmeans_clusters: int, optional (default=10) |
There was a problem hiding this comment.
I think that we could make this a KMeans estimator instead.
I am thinking that it could be interesting to plug a MiniBatchKMeans for instance which could be quicker to converge and memory efficient. This could be the default. However, it let people to be able to pass a KMeans classifier if interested.
There was a problem hiding this comment.
Completely agree, MiniBatchKMeans is now the default and a test has been included to ensure that using a "normal" kmeans instance will also work.
|
I merged #440, you should be able to create a new class. |
|
@StephanHeijl thanks. @felix-last @glemaitre do you have time for a review? |
There was a problem hiding this comment.
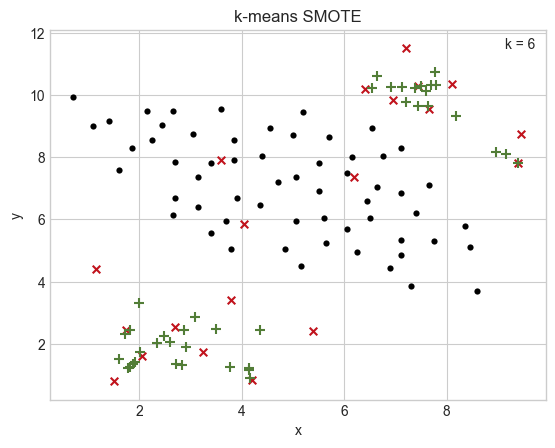
As a sanity check, I tried creating some of the toy dataset plots from our paper using this implementation.
For some examples this implementation yields unwanted results. Of course, we couldn't expect results to be exactly the same, but it could also be a hint that something is wrong (or that I'm overlooking something or it's just an unlucky random seed). I tried translating our implementation's default parameters (which I used for the toy plots in the paper) to the corresponding parameters of this implementation.
Comparison our implementation (left) vs. this implementation (right)
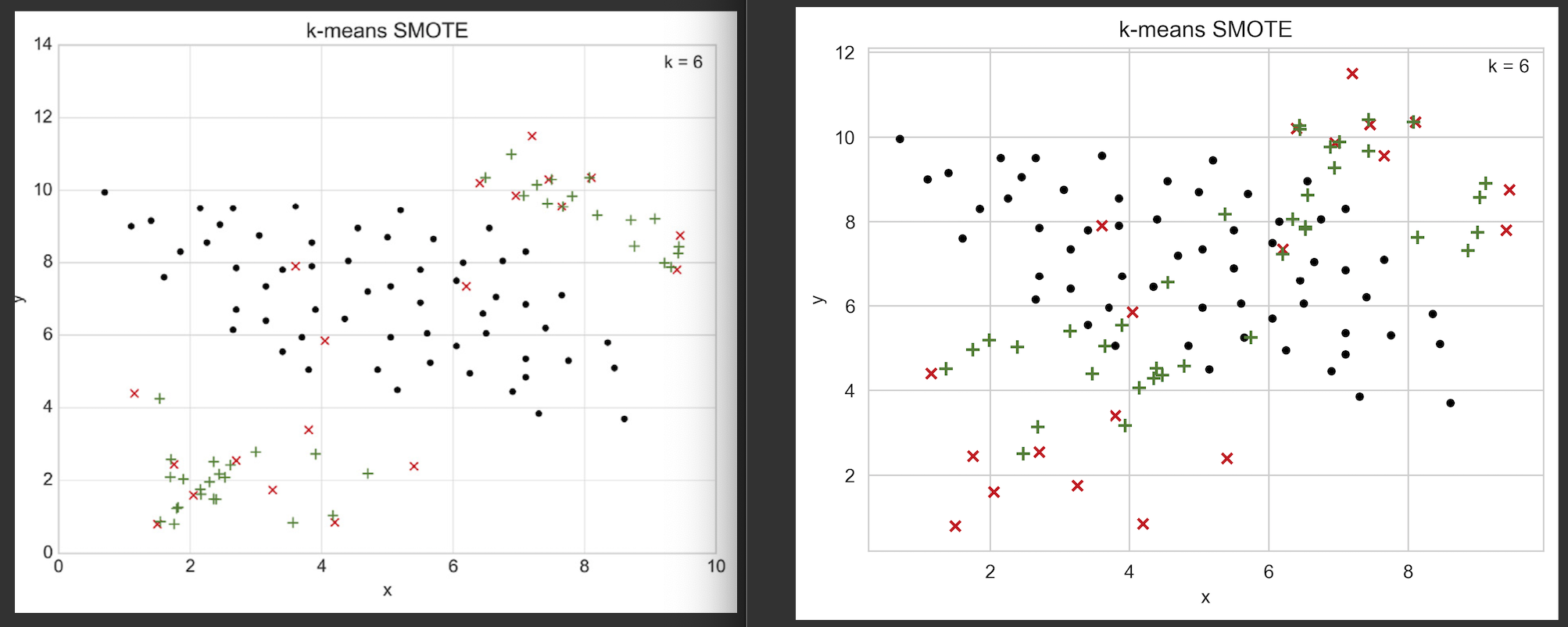
After a quick glance, the code looks good to me.
Feel free to play around with the plotting script. Prerequisites are to install requirements.txt, install this PR's imblearn and create a config.yml with a results_dir and dataset_dir. Download the toy datasets into the datasets dir. For comparison, here's all the toy plots obtained from our implementation: kmeans-smote-figures.zip.
|
@felix-last Thank you very much for taking the time to look into this! It appears that I entered a wrong parameter for the I have updated the tests and the script in accordance with this improvement. |
| Use the parameter ``sampling_strategy`` instead. It will be removed | ||
| in 0.6. | ||
|
|
||
| """ |
There was a problem hiding this comment.
At the end of the docstring we could add the reference of the paper and after that an interactive example. Check here for instance.
There was a problem hiding this comment.
I added an interactive example that specifically demonstrates the utility of the KMeansSmote class, 3 blobs, with the positive class in the middle and the negative classes on the outside and a single negative sample in the middle blob. The example shows that after resampling no new samples are added in the middle blob. Inspired by the following toy problem:

|
@chkoar I have attended to your proposed changes, I hope this covers enough of an interactive example. |
|
@StephanHeijl could you please rebase your branch so we can finally merge this pr? |
|
I made the push to solve the conflict. I will review and make couple of changes regarding the style if necessary and merge it. |
What does this implement/fix? Explain your changes.
This pull request implements K-Means SMOTE, as described in Oversampling for Imbalanced Learning Based on K-Means and SMOTE by Last et al.
Any other comments?
The density estimation function has been changed slightly from the reference paper, as the power term yielded very large numbers. This caused the weighting to favour a single cluster.